GPT4V.net utilizes OpenAI’s most powerful GPT4V interface, which has undergone productization modifications, we provide users with advanced and stable GPT4V conversational services.
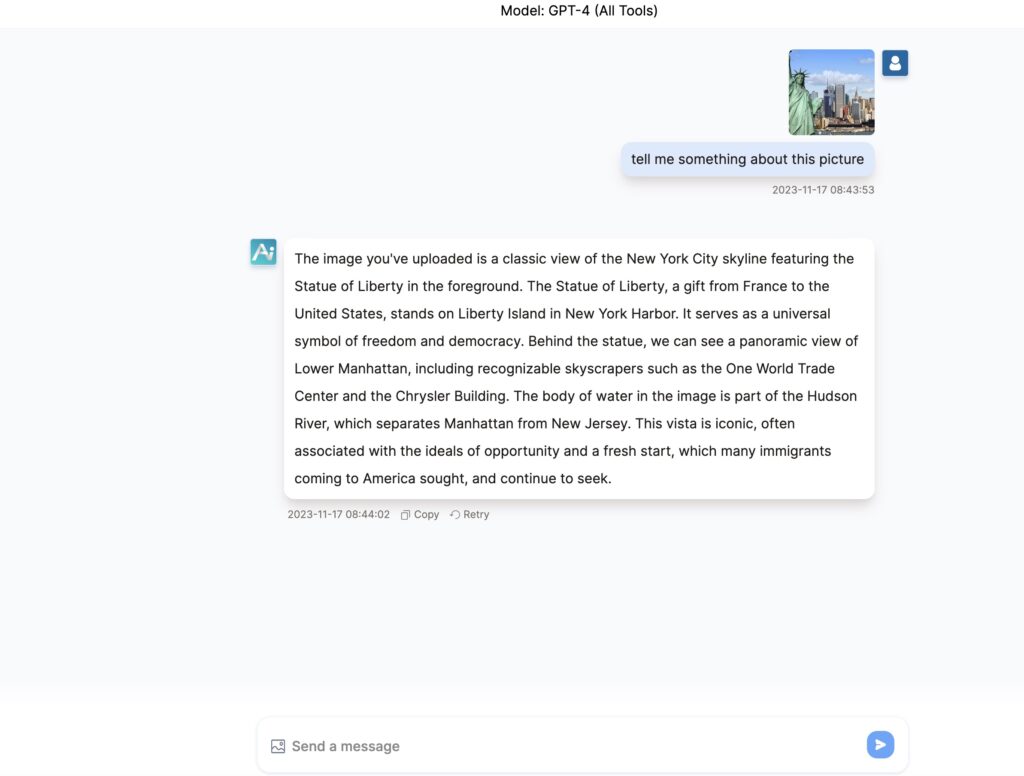
1. Multimodal Capabilities: GPT-4V is a multimodal model that allows users to upload an image as input and ask questions about it, a process known as visual question answering (VQA). This positions GPT-4V within the category of Large Multimodal Models (LMMs), capable of processing information in multiple modalities such as text and images or text and audio
2. Range of Functionalities: GPT-4V is designed to perform a variety of tasks including Visual Question Answering (VQA), Optical Character Recognition (OCR), Math OCR, Object Detection, Reading CAPTCHAs, and solving Crosswords and Sudokus.
3. Automatic Judgment for Internet-Based Information Retrieval: GPT-4V has the capability to autonomously determine if a query requires internet-based information. If necessary, it can automatically conduct fresh information searches and combine these findings with GPT-4’s analytical abilities to provide a comprehensive response.
4. Each user can use it for free 10 times a day, allowing for convenient and smooth usage.