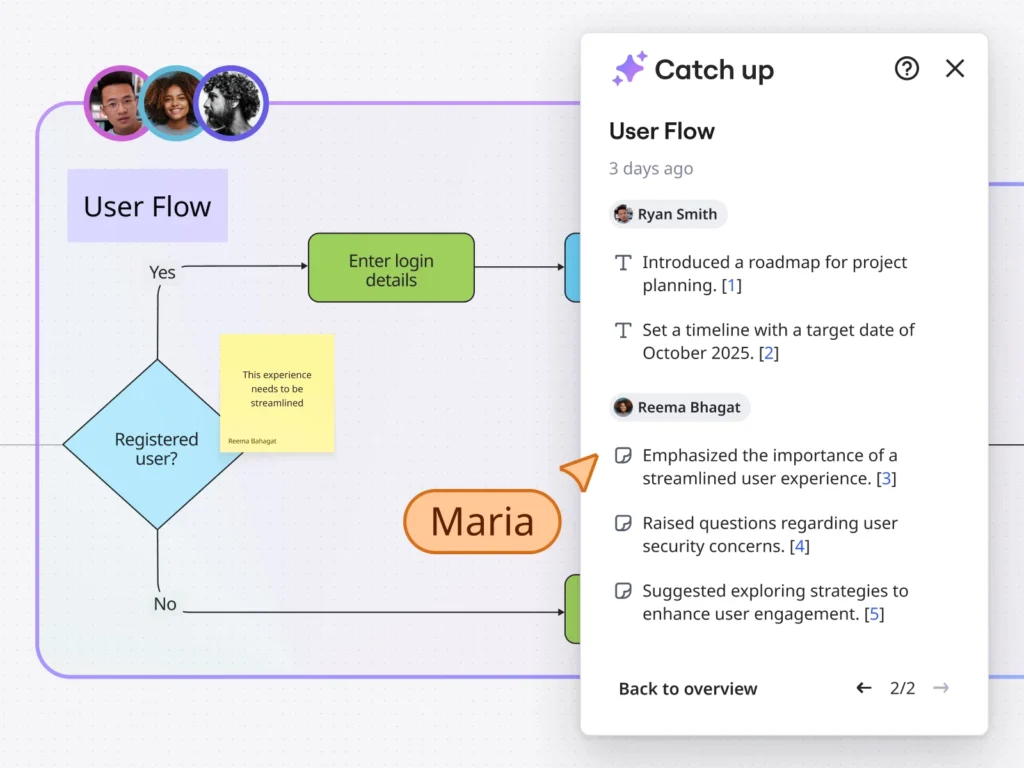
AgentQL is an LLM-based dev infrastructure for data scraping and workflow automation.
For data scraping usage, it lets you select data with natural language instead of navigating DOMs, creates code resilient to UI changes, and enables code deployment to other sites.
You can easily try it out in seconds in this interactive playground https://playground.agentql.com/.
Conventional web scraping soaks up dev time as intricate DOM structures and unpredictable AJAX-driven content updates complicate the development of robust extraction algorithms; isolating high-quality data in the correct format from unstructured web information is a long-standing challenge. Scraping scripts are tailored to the unique quirks of individual web pages, and cannot be reused for other sites, requiring constant customization. Maintaining scraping scripts to accommodate web UI changes is an endless task.
AgentQL simplifies the process of locating web elements. With its natural language-like query syntax, developers can specify web elements without diving into complex DOM structures or writing fragile XPath expressions. Core to the tool is AgentQL Query, a query language designed to give users an easy way to describe what web elements to locate on a given web page.
At its core, we’ve melded sophisticated prompt engineering with a robust LLM. This powerful combo dynamically generates context-aware prompts that interact with the DOM’s mutable attributes, adapting to the ever-changing web landscape. This mitigates the traditional fragility of static XPath or CSS selector-based scripts, allowing for more resilient and adaptable integrations.
AgentQL
Painless Data Extraction and Web Automation
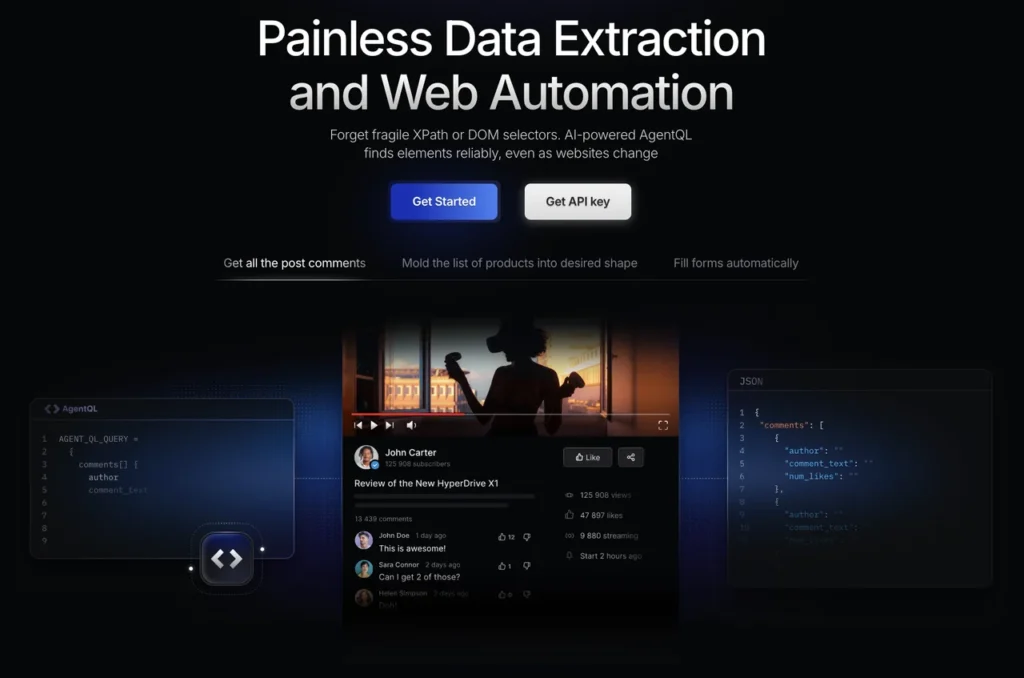
Overview
Key Features of AgentQL
AgentQL is an LLM-based dev infrastructure for data scraping and workflow automation.
For data scraping usage, it lets you select desired data with natural language instead of navigating DOMs, creates code that is resilient to dynamic UI changes, and lets you reuse that code to scrape other sites. You can play with it in the interactive playground (LINK) or test it out with free credits (LINK).
So conventional web scraping soaks up dev time in four ways:
(1) The intricate DOM structures and unpredictable AJAX-driven content updates complicate the development of robust extraction algorithms.
(2) Isolating high-quality data in the correct format from the ocean of unstructured web information is a long-standing challenge.
(3) Scraping scripts are tailored to the unique quirks of individual web pages, and cannot be reused for other sites. This leads to continuous cycles of customization and adaptation.
(4) Updating scraping scripts to accommodate web UI changes is an endless task.
AgentQL simplifies the process of locating web elements. With its natural language-like query syntax, developers can specify web elements without diving into complex DOM structures or writing fragile XPath expressions.
AgentQL Use Cases
AgentQL simplifies the process of locating web elements. With its natural language-like query syntax, developers can specify web elements without diving into complex DOM structures or writing fragile XPath expressions. Core to the tool is AgentQL Query, a query language designed to give users an easy way to describe what web elements to locate on a given web page.
At its core, we’ve melded sophisticated prompt engineering with a robust LLM. This powerful combo dynamically generates context-aware prompts that interact with the DOM’s mutable attributes, adapting to the ever-changing web landscape. This mitigates the traditional fragility of static XPath or CSS selector-based scripts, allowing for more resilient and adaptable integrations.
Check it out
Check out AgentQLTags
Dev
Lorka AI
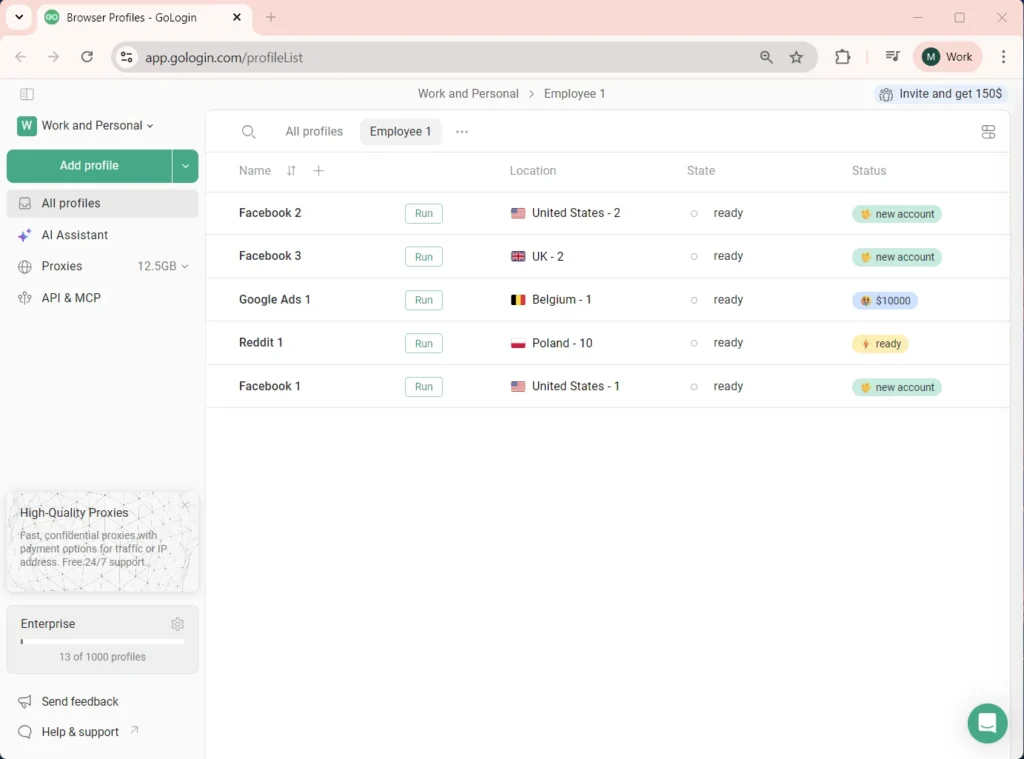
Gologin Cloud Browser
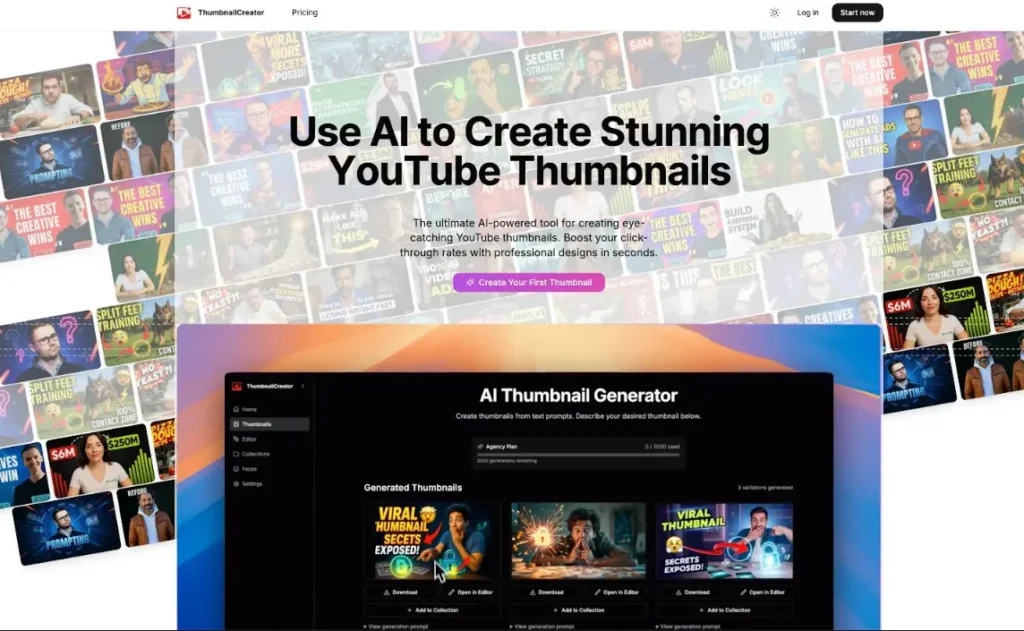
ThumbnailCreator.com
Homesage.ai
pxz