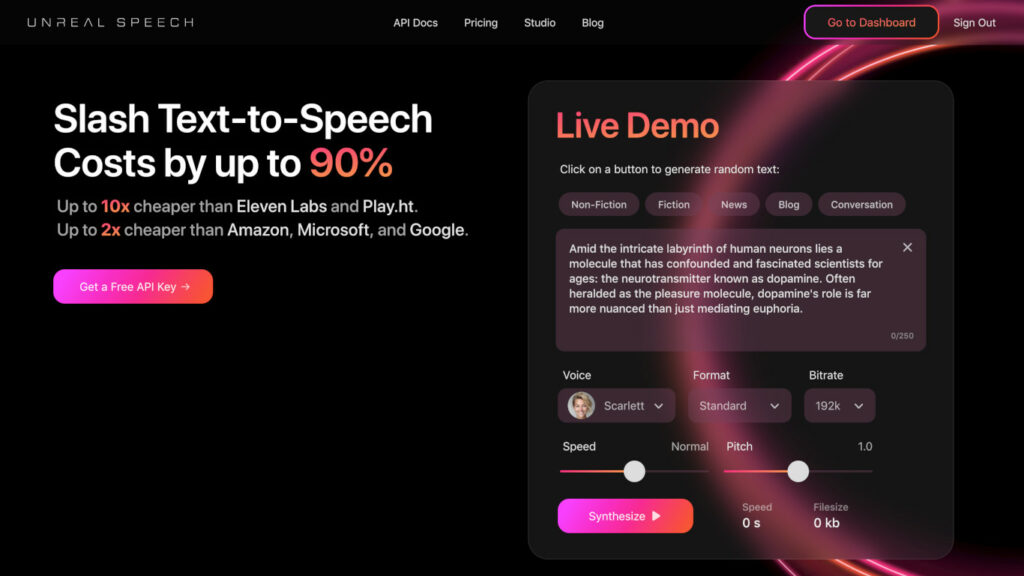
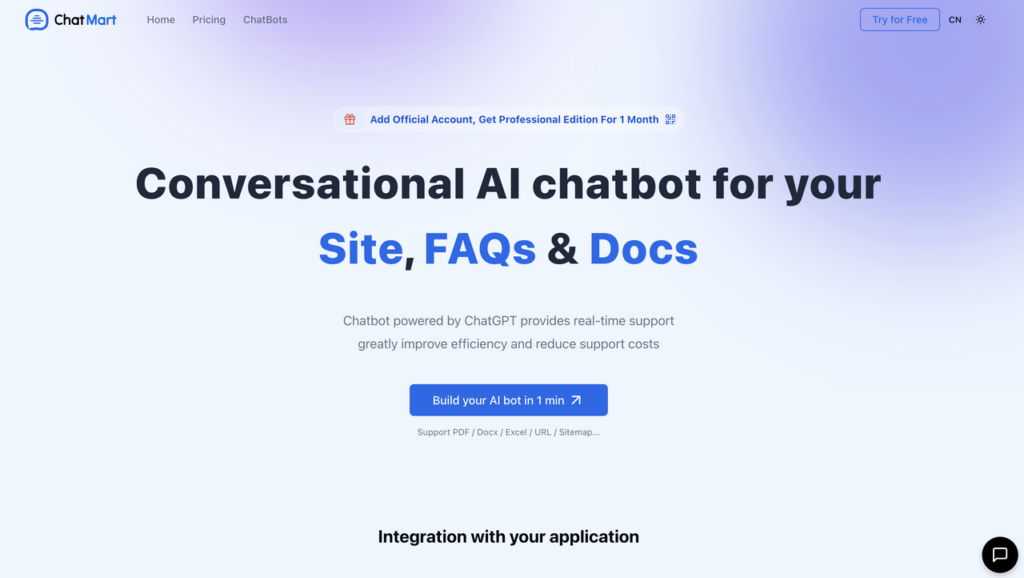
ChatMart - Conversational AI chatbot for your Site, FAQs & Docs. Use AI-powered chatbot to empower your users and reduce support costs.
ChatMart can be integrated into channels like WhatsApp, Shopify, Wordpress, and more to meet all your needs.
Use cases: Document summarization, document dialogue, knowledge sharing, research for papers/reports, teaching assistants, corporate training, customer support, website search, shopping guide recommendations, sales support, and more.
Of course, you can customize the model and data to explore more use cases and meet any of your needs.
advantage:
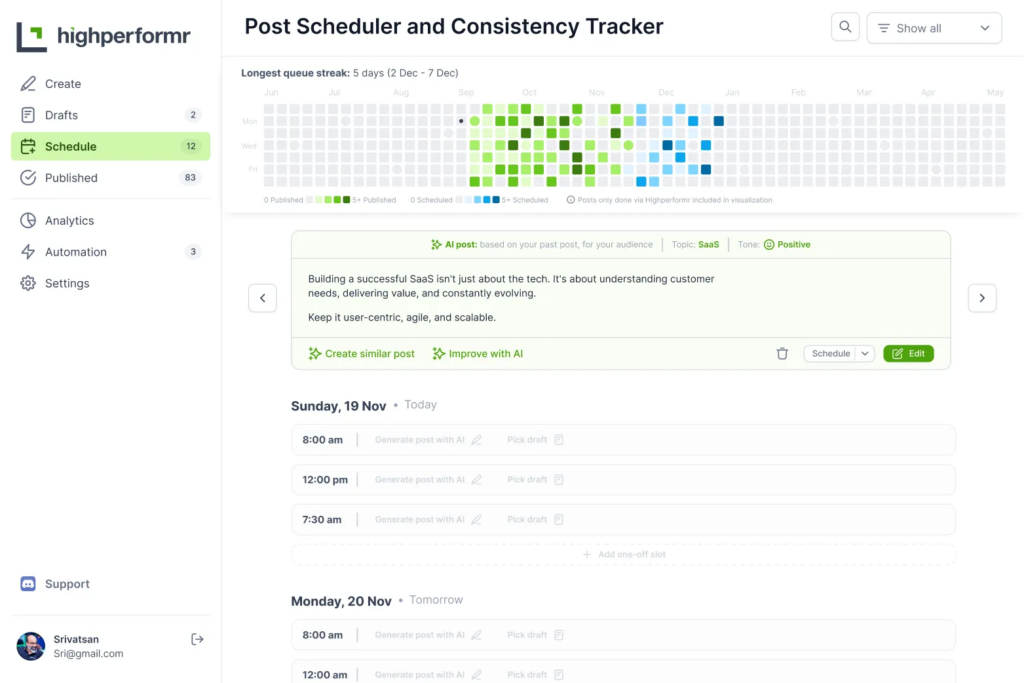
- Provide website links or sitemap links, and upload files to add your content.
- Supports all file types, including PDF, TXT, Docx, Excel, etc.
- Accurate document understanding, real-time response.
- Various types of Agents: Document Assistant, Thesis Assistant, Customer Service Assistant, etc.
- Capable of collecting user information to acquire more potential customer leads.
- Customizable chat interface, tailored to fit the brand image.
- Integration into any channel: WhatsApp, Shopify, Wordpress, Facebook, etc.
- Supports dark/light mode.
- Free and Premium versions: Basic usage is free, and advanced packages are available for purchase for additional needs.
- Rich API options.